2025. 3. 4. 14:57ㆍKubernetes/AutoScaling
# 테스트 환경
- OS : Ubuntu 24.04 LTS
- kubectl : v1.30.0
Kubernetes의 autoscaling 방법 중 하나인 VAP를 이용한 autoscaling 테스트를 진행하였다.
VPA (Vertical Pod Autoscaler)
vertical pod autoscaler는 pod의 리소스 요청과 제한 값을 자동으로 조절해 주는 autoscaling 도구이며 CPU와 메모리 사용량을 모니터링하고 필요에 따라 pod의 리소스 설정을 동적으로 조정하여 성능 최적화를 도와준다.
주요 기능
1. 리소스 최적화 : 실제 사용량에 맞게 CPU와 메모리 요청 및 제한을 조절하여 불필요한 리소스 낭비를 줄인다.
2. 수직 스케일링 : pod의 개수는 유지한 채 개별 pod의 리소스를 확장 또는 축소한다.
3. 다양한 모드 지원
- off : 리소스를 추천만 하고 실제로 변경은 하지 않는다.
- Auto : 자동으로 리소스를 조절하고 pod를 재 시작한다.
- Initial : 처음 생성 시에만 리소스를 설정하고 이후에는 변경하지 않는다.
추가적으로 주요 기능은 아니지만 참고해야 할 사항은 아래와 같다.
리소스 변경 시 pod가 재 시작 되기 때문에 서비스 중단 가능성을 반드시 고려해야 한다.
구성 요소
1. VPA Recommender
pod의 CPU 및 메모리 사용량을 수집하고 분석하며 적절한 리소스 요청과 제한을 계산하는 역할을 수행한다.
VPA 객체의 status 필드에 추천 값을 저장한다.
2. VPA Updater
Recommender에서 계산한 값과 현재 리소스를 비교하여 차이가 클 경우 해당 pod를 재 시작해 새로운 리소스를 적용한다.
pod 재 시작 없이 리소스 변경은 불가능하기 때문에 pod를 삭제한 후 재 생성한다.
3. VPA Admission Controller
새로운 pod가 생성될 때 초기 리소스를 설정하는 역할을 수행한다.
(updateMode: "Initial" 일 때만 해당 controller가 동작)
동작 과정
1. metrics server에서 pod의 실시간 메모리 및 CPU 사용량을 수집
2. Recommender가 리소스 추천 값을 계산하여 추천
- Lower Bound : 최소로 필요한 리소스
- Target : 평균적인 리소스 사용량 (권장값)
- Upper Bound : 최대 필요한 리소스
3. 리소스 조정
- off : 리소스를 추천만 하고 변경은 진행하지 않음
- initial : 새로운 pod 생성 시 초기 리소스만 추천 값에 맞게 설정
- auto : pod의 리소스를 변경하고 재 시작
Test Case (auto)
자동으로 환경에 맞게 리소스 할당량을 추천해 주고 새로 pending 되는 pod에 대해 해당 리소스 할당량을 적용하여 새로운 pod를 띄워 준다.
vpa-memory-test.yaml
deployment name : vpa-memory-test
최초 생성 pod 수 : 1개
apiVersion: apps/v1
kind: Deployment
metadata:
name: vpa-memory-test
labels:
app: vpa-memory-test
spec:
replicas: 1
selector:
matchLabels:
app: vpa-memory-test
template:
metadata:
labels:
app: vpa-memory-test
spec:
containers:
- name: memory-stress
image: busybox
command:
- sh
- -c
- |
i=0
max_load=512 # 최대 메모리 부하(MiB)
while true; do
if [ "$i" -lt "$max_load" ]; then
echo "메모리 부하 증가: ${i}Mi"
dd if=/dev/zero of=/tmp/memory_stress bs=1M count=64 &
i=$((i + 64)) # dd 명령을 사용하여 /dev/zero에서 /tmp/memory_stress 파일에 64Mi 단위로 데이터 기록
else
echo "최대 메모리 부하에 도달. 부하 감소 시작"
while [ "$i" -gt 0 ]; do
echo "메모리 부하 감소: ${i}Mi"
rm -f /tmp/memory_stress
sleep 2
i=$((i - 64)) # 64Mi씩 감소
done
echo "부하 감소 완료. 초기화 중..."
fi
sleep 2
done
resources:
requests:
memory: "256Mi" # 최소 256Mi 메모리 보장
cpu: "100m"
limits:
memory: "512Mi" # 최대 256Mi 메모리 보장
cpu: "500m"
위의 yaml 파일은
- 매 2초마다 64 MiB씩 메모리 부하를 생성
- 최대 512 MiB까지 메모리를 소비
- 512MiB에 도달하면 64 MiB씩 줄이면서 메모리를 해제
deployment에 맞게 auto 방식의 vpa를 적용하기 위한 yaml 파일은 아래와 같다.
vpa-auto.yaml
vpa name : vpa-test-auto
업데이트 정책 : auto
→ 자원의 사용량을 모니터링하고 필요시 Pod를 재 시작하여 requests 값을 업데이트한다.
---
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: vpa-test-auto
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: vpa-memory-test
updatePolicy:
updateMode: "Auto" # 자동으로 리소스 변경 및 Pod 재시작
resourcePolicy:
containerPolicies:
- containerName: stress-test
minAllowed:
cpu: "50m"
memory: "64Mi"
maxAllowed:
cpu: "2"
memory: "2Gi"
위의 yaml 파일은
- CPU 사용량은 0.05 ~ 2 vCPU 범위에서 자동 조정
- 메모리는 64Mi ~ 2Gi 범위에서 자동 조정
Test 결과
먼저 vpa-memory-test.yaml과 vpa-auto.yaml 파일을 apply 명령어를 통해 배포
# deployment apply
kubectl apply -f vpa-memory-test.yaml
# vpa apply
kubectl apply -f vpa-auto.yaml
최초에 apply 명령어를 통해 생성한 deployment와 vpa를 확인
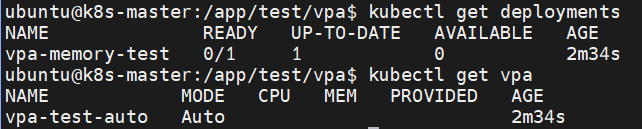
deployment를 통해 특정 조건을 가진 pod가 Pending - Creating - Running 상태 순서로 테스트가 진행이 되고 지속적인 부하로 인해 결국 Pod의 상태가 Error 상태가 되게 된다.
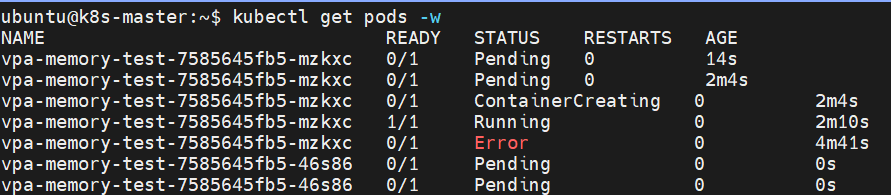
이때 배포 되어 있는 vpa인 vpa-test-auto를 describe 해보게 되면 Lower Bound와 Upper Bound, Target이 측정되어 해당 정보를 볼 수 있게 된다.
이 부분이 vpa가 시스템 리소스에 대한 정보를 수집하여 환경에 맞게 리소스 추천 값을 계산하여 보여주는 부분이다.
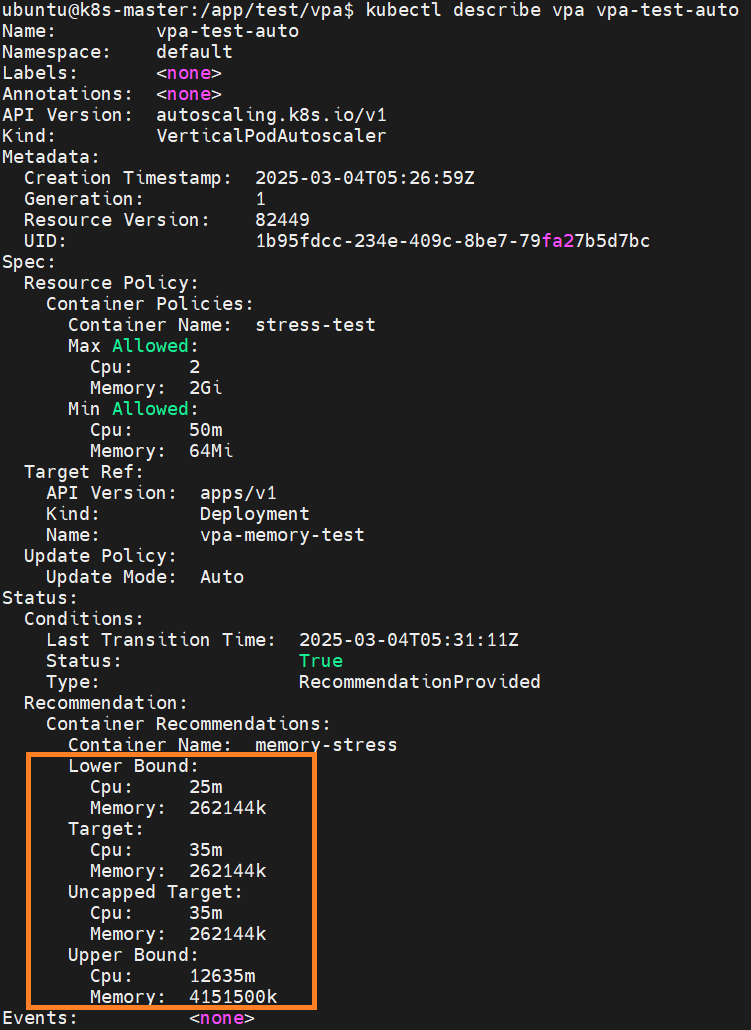

현재 test하고 있는 vpa의 auto 설정의 경우 리소스 추천 값을 새로운 파드를 띄울 때 적용하여 생성한다.
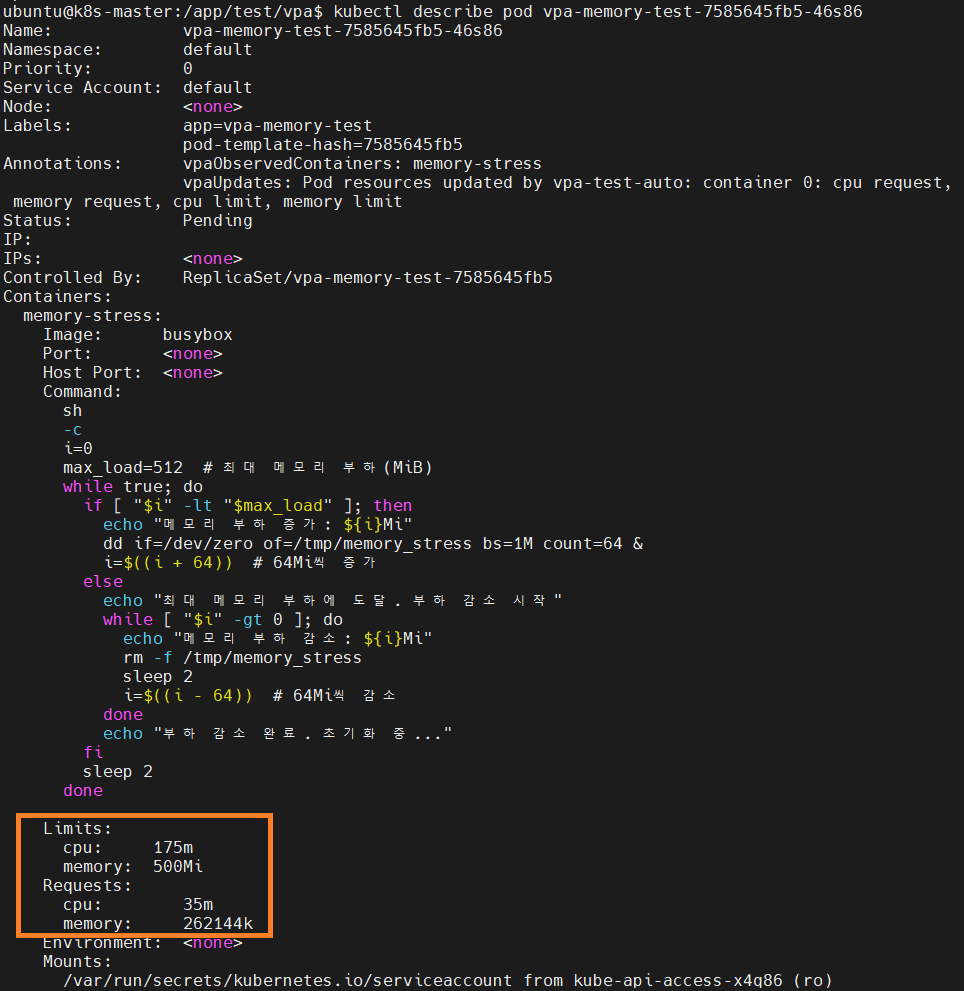
먼저 새로운 파드가 Pending 되고 Creating 되고 있는지 pod 조회를 진행한다.
최초에 생성된 mzkxc 말고 46s86 pod가 Pending - Creating - Running 상태로 생성이 된 것을 확인할 수 있다.
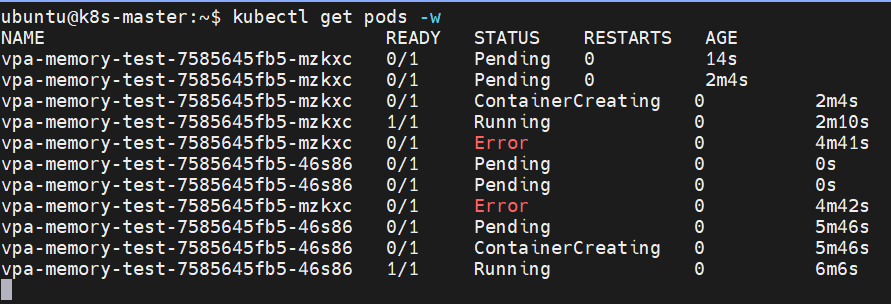
또한 새로 생성된 pod에 대한 정보를 describe 하게 되면 아래와 같이 추천 값이 적용된 것을 확인할 수 있다.
'Kubernetes > AutoScaling' 카테고리의 다른 글
| VPA를 이용한 autoscaling 테스트 - off (0) | 2025.03.04 |
|---|---|
| metrics server와 HPA를 이용한 autoscaling 테스트 (0) | 2025.02.25 |